Python爬取笑话
Python爬取笑话排行,将数据以json存储到文件中
我们爬取的地址是:http://www.jokeji.cn/hot.asp?action=brow
分析一下,我们需要爬取总页数,然后读取每页下面的笑话,笑话内容需要去详情页去爬取
1、首先我们创建一个程序入口
- 我们创建一个文件夹,文件夹里最后存数据文件进去
- spider(root_url) 方法开始爬取数据,这个方法我们自己实现
1
2
3
4
5
6
7
8
9
10
11
|
if __name__ == "__main__":
importlib.reload(sys)
if os.path.isdir(root_folder):
pass
else:
os.mkdir(root_folder)
spider(root_url)
print('**** spider ****')
|
2、开始爬取数据spider(root_url)
- 先去getpages(url)获取页数pages,后面会讲到
- page(pageurl)获取每页里面数据
- 数据爬完,存储到data.json文件中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
def spider(url):
list1 = []
i = 1
pages = getpages(url)
while i <= int(pages):
pageurl = 'http://www.jokeji.cn/hot.asp?action=brow&me_page='+str(i)
print(pageurl)
list1 = list1+page(pageurl)
i = i+1
pass
else:
print('大于页数')
try:
filename = root_folder + 'data.json'
with open(filename, "wb") as f:
stri = json.dumps(list1, encoding='UTF-8', ensure_ascii=False)
print(stri)
f.write(stri)
pass
except Exception as e:
print('Error:', e)
pass
pass
|
3、获取页数getpages(url)
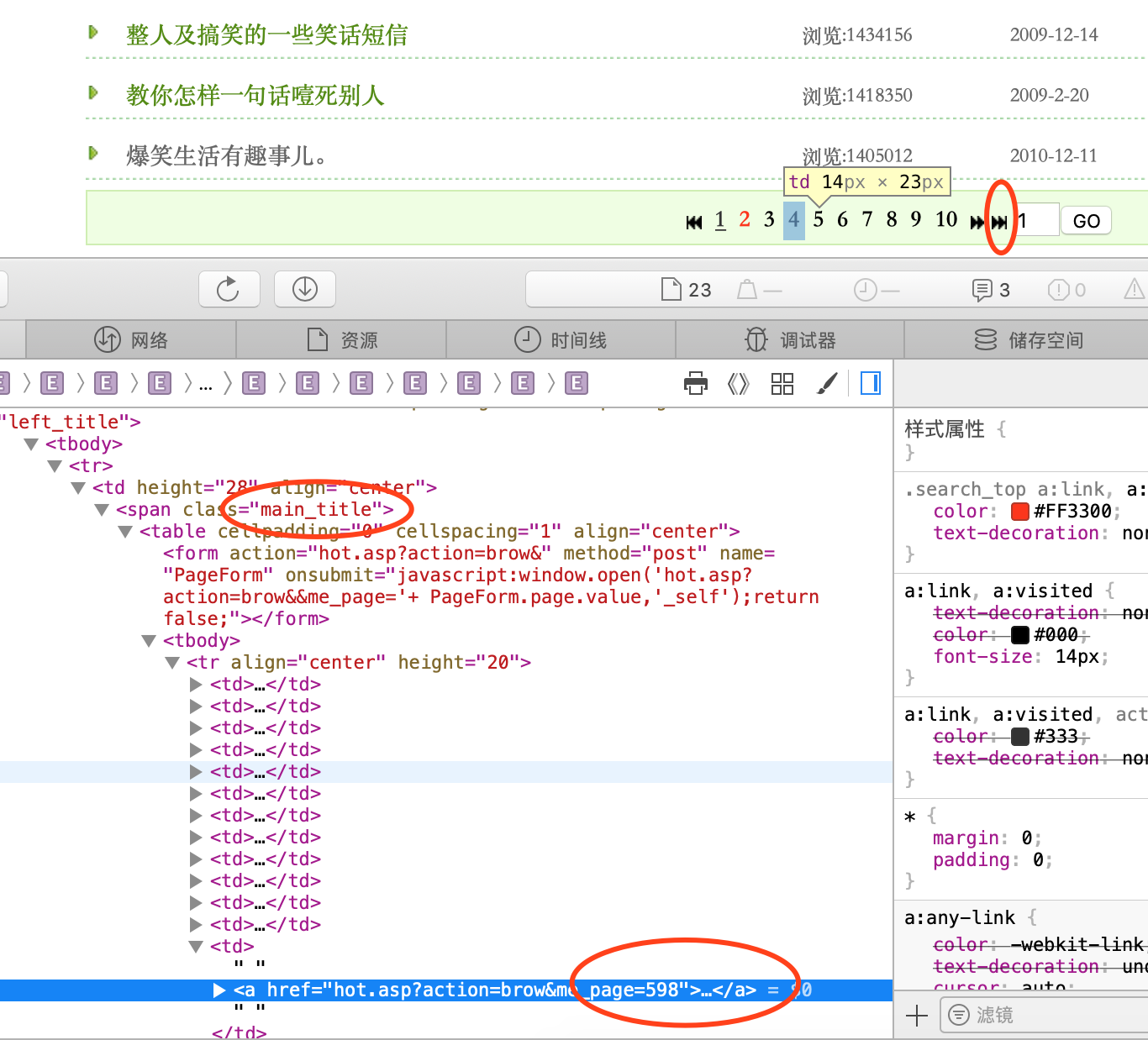
找最后一页的逻辑(如图),最后一页在这个>>按钮里面,我们看源码,可以看到598,598就是总的页数了,接下来就是怎么获取这个页数。我们找到Class=”main_title”,然后找这main_title下面的所有td,我们所要的598就在倒数第二个td中,最后处理字符串,取出598。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
def getpages(url):
print(url)
url = quote(url, safe=string.printable)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
http = urllib3.PoolManager()
web_data = http.request('GET', url, headers=headers).data
soup = BeautifulSoup(web_data, 'html.parser', from_encoding='GBK')
print(web_data)
span = soup.find(class_='main_title')
tds = span.findAll('td')
td = tds[len(tds)-2]
pages = td.select('a')[0].get('href').replace('hot.asp?action=brow&me_page=', '')
print(pages)
return pages
|
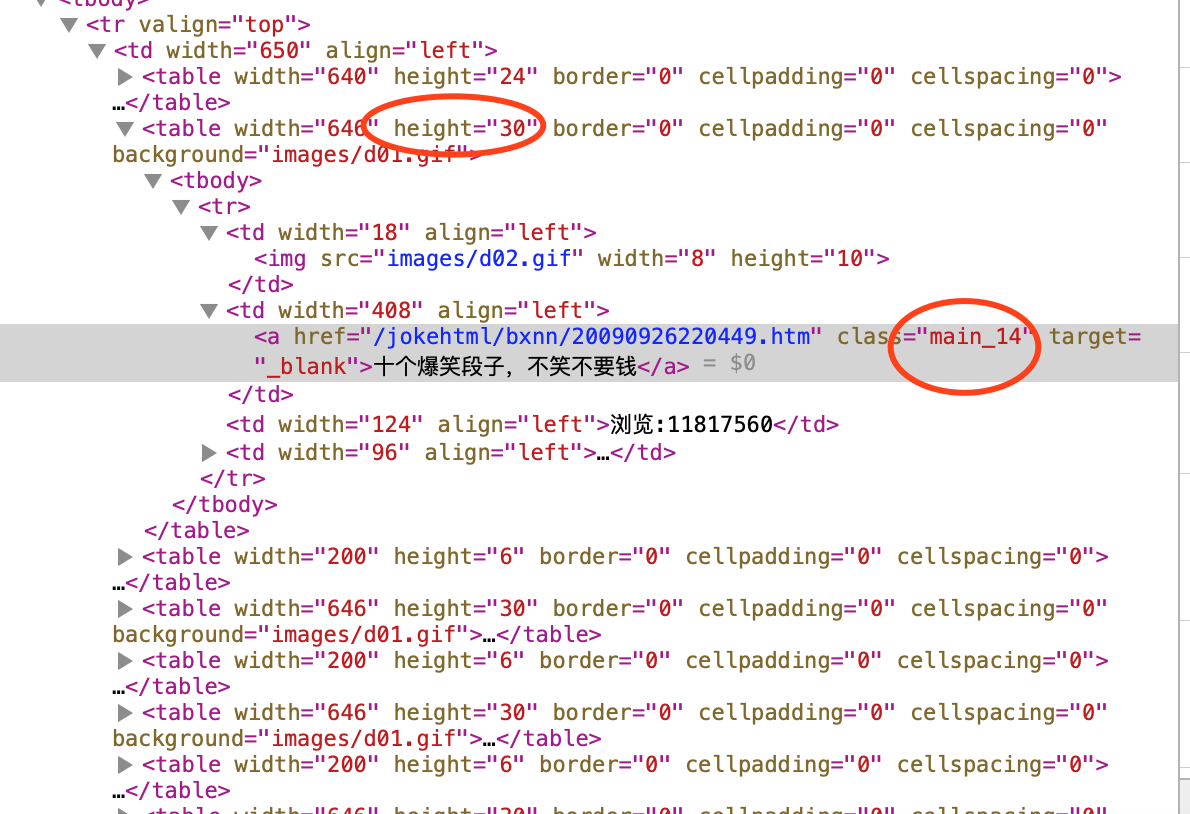
4、page(pageurl)获取每页里面数据
getmeichannel(url)获取当前页下面的笑话列表
然后再detail(herf)去爬取每个笑话的详情
爬取逻辑看图:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def page(url):
channel_list = getmeichannel(url)
list1 = []
for tr in channel_list:
dict1 = {}
a = tr.find(class_='main_14')
herf = 'http://www.jokeji.cn'+a.get('href')
title = a.get_text()
print(str(herf)+' --- '+str(title))
dict1['herf'] = herf
dict1['title'] = title
dict1['date'] = tr.find(class_='date').get_text().replace('\r\n ', '')
dict1['detail'] = detail(herf)
list1.append(dict1)
return list1
|
5、getmeichannel(url)获取当前页下面的笑话列表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
def getmeichannel(url):
url = quote(url, safe=string.printable)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
http = urllib3.PoolManager()
web_data = http.request('GET', url, headers=headers).data
soup = BeautifulSoup(web_data, 'html.parser', from_encoding='GBK')
channel = []
tables = soup.findAll(height='30')
for table in tables:
try:
for tr in table.findAll('tr'):
channel.append(tr)
pass
except Exception as e:
print('Error:', e)
pass
return channel
|
6、获取详情数据detail(herf)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def detail(url):
url = quote(url, safe=string.printable)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
http = urllib3.PoolManager()
r = http.request('GET', url, headers=headers)
web_data = r.data
soup = BeautifulSoup(web_data, 'html.parser', from_encoding='GBK')
font = soup.find(attrs={'id': 'text110'})
try:
return font.get_text()
pass
except Exception as e:
print(str(e))
return ''
pass
|
源码地址https://github.com/whde/Joke.git